You type a question into ChatGPT, perhaps wondering about the weather in Tokyo, or seeking advice on a tricky piece of Python code. As you press send, this text is whisked away to a data centre, where it undergoes a transformation. The words you typed are broken into tokens—small chunks that typically represent a word or part of a word, each about four characters long on average. These tokens are not just left in their textual form; they are converted into long lists of numbers, known as vectors. These vectors are then fed into a vast neural network—think hundreds of billions to over a trillion adjustable parameters in a cutting-edge model by 2026. This network conducts a series of complex mathematical operations on the vectors, ultimately producing a probability distribution over a vocabulary of around 100,000 potential next tokens. From this distribution, the model selects one token—sometimes the most probable, sometimes a slightly less likely one—to append to your original text. This selection process is repeated, adding one token at a time, until a stop signal is generated. The rapid sequence of these operations, happening dozens or even hundreds of times per second, creates the coherent text that appears on your screen.
What a token is
Tokens are fundamental to how language models process text. A computer cannot directly interpret text as a human does; instead, it converts text into numbers. This conversion begins with tokenisation. In modern language models, tokenisation often employs a method called byte-pair encoding (BPE). BPE starts with a vocabulary of single characters and iteratively merges the most frequent character pairs to form larger and more meaningful tokens until a predetermined vocabulary size is reached. This process enables the model to handle common words like 'the' as single tokens while breaking rarer or longer words into smaller pieces—for instance, 'unbelievable' might be tokenised as 'un', 'believ', and 'able'. Additionally, punctuation and spaces become discrete tokens. In practical terms, an English sentence with 20 words might translate to 25-35 tokens.
The model's capacity to handle input is measured in terms of a 'context window', which refers to the number of tokens it can process simultaneously. Frontier models, as of 2026, boast context windows capable of accommodating up to one million tokens, equivalent to approximately 750,000 English words or several novels in length. This expansive capacity allows the model to understand and generate coherent responses by considering a significant amount of contextual information, making interactions more natural and contextually relevant.
What an embedding is
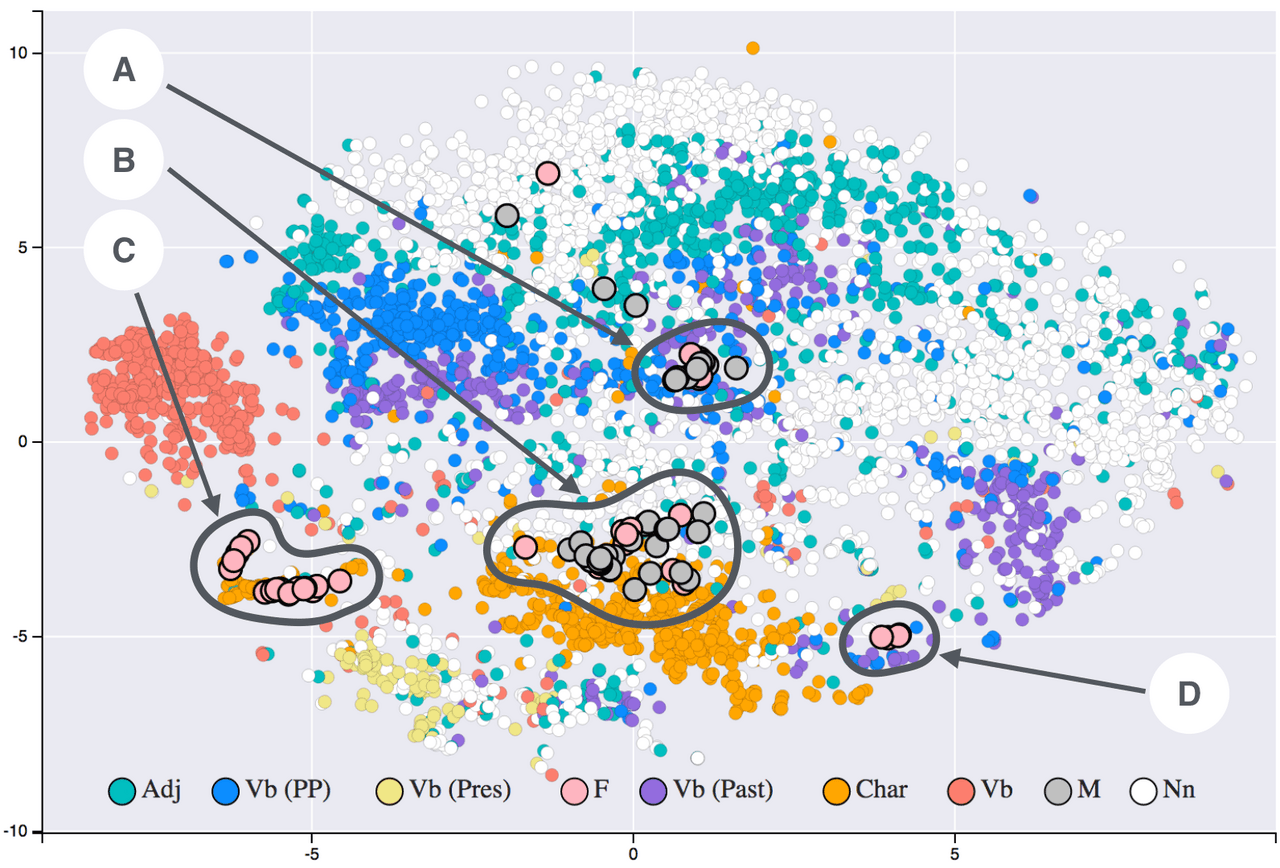
Once text has been tokenised, each token is transformed into an embedding—a vector of numbers, often in thousands of dimensions. These embeddings are crucial as they encapsulate the semantic essence of the token. The fascinating aspect of embeddings is their ability to reflect semantic relationships: tokens with related meanings have similar embeddings, while unrelated ones do not. For example, 'king' and 'queen' share proximal embeddings, while 'king' and 'spaghetti' do not.
This embedding process is not manually designed but learned during training. The model observes which tokens frequently appear together in diverse contexts and adjusts embeddings accordingly. A seminal demonstration of this phenomenon was by Mikolov et al. (2013) with word2vec, where it was shown that the embedding of 'king' minus 'man' plus 'woman' approximately equalled the embedding of 'queen'. Modern transformer models have taken this concept further, employing contextual embeddings that adjust dynamically according to the sentence. For instance, the word 'bank' will have different embeddings depending on whether it appears in 'river bank' or 'bank account', showing the model's ability to discern context on-the-fly.
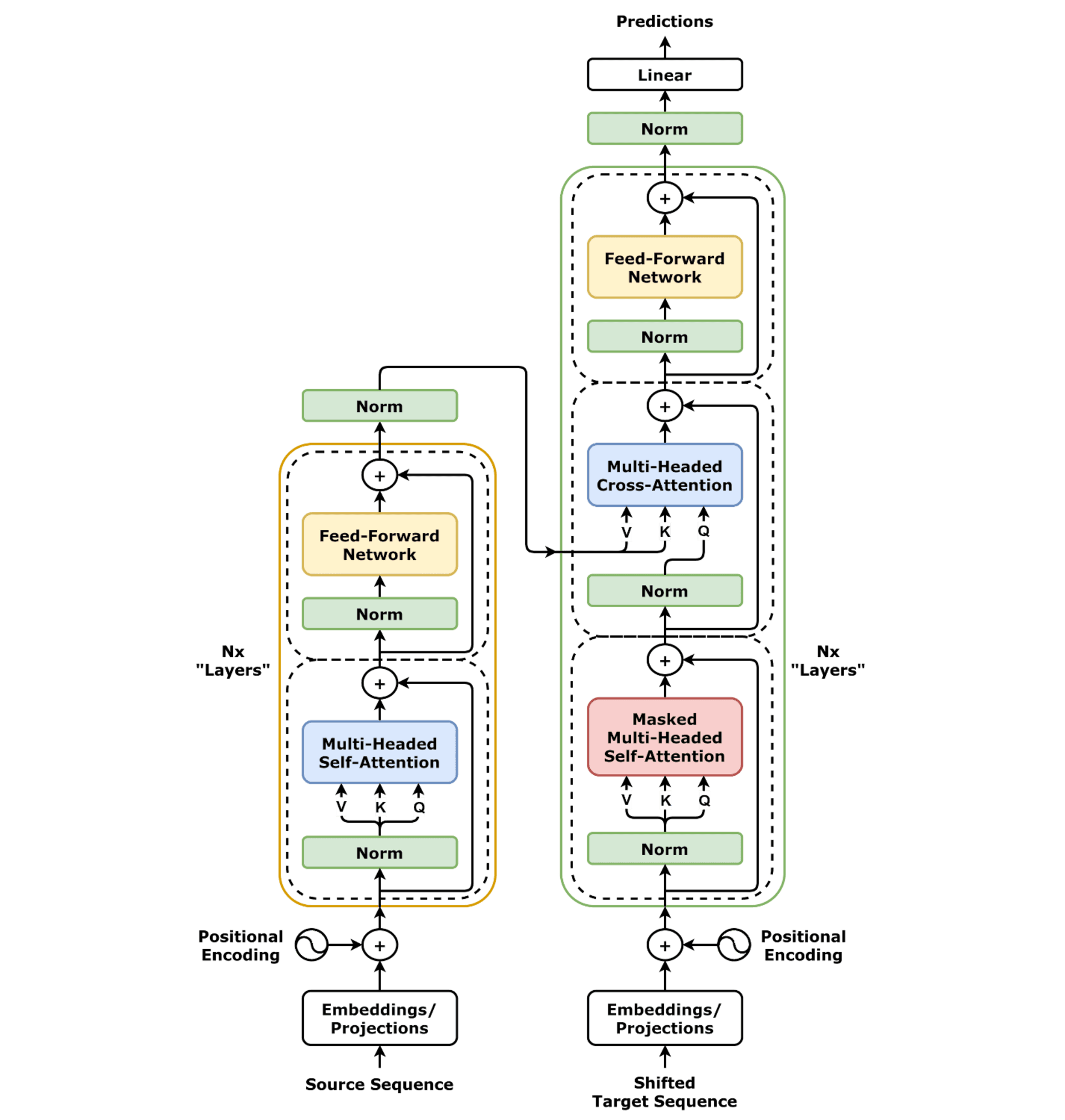
What attention is
A pivotal advancement in language modelling came with the introduction of the transformer architecture, prominently featuring self-attention, as described by Vaswani et al. in 2017. Self-attention allows a model to determine which parts of the input are most relevant to understanding each token, assigning weights to these parts accordingly. Consider the sentence, 'The cat sat on the mat because it was tired.' When processing the word 'it', the attention mechanism assigns high relevance to 'cat', as it is the noun most likely to be tired, thus understanding the grammatical and contextual relationship.
Self-attention does not operate in isolation but in parallel, across all input positions and multiple 'heads'—typically 32-128 parallel attention mechanisms per layer. These heads enable the model to examine different aspects of the input simultaneously. The architecture comprises multiple layers of these attention mechanisms, each building upon the representation provided by the previous one. By the end of this multi-layered processing, each token's representation within the model reflects a comprehensive understanding of the entire input sequence.
How it was trained
The development of these models relies heavily on training—a process governed by gradient descent and back-propagation. The model's parameters, which define its computational behaviour, are optimised over vast datasets through these methods. Training involves presenting the model with text, omitting the last token, and having it predict this missing part. The predicted probabilities are compared with the actual next token to compute the error or 'loss'. The model then adjusts its parameters slightly to minimise this loss in future predictions.
This adjustment process, known as back-propagation, is applied across a dataset of roughly 10 trillion tokens from diverse sources, including internet text, books, and code. Training a frontier model can span weeks, utilising tens of thousands of GPUs and costing tens of millions of dollars. The end result is a model with internalised patterns of text from vast corpora. To refine these patterns further, post-training phases involve supervised fine-tuning with human examples and reinforcement learning from human feedback (RLHF), as detailed by Ouyang et al. (2022), steering the model towards outputs that are considered helpful, harmless, and truthful by humans.
Why nobody quite knows why scale works
A striking discovery in the evolution of language models is the emergence of new capabilities as models scale in size. For instance, GPT-2, with 1.5 billion parameters, struggled with arithmetic, whereas GPT-3, with 175 billion parameters, managed basic arithmetic for familiar numbers. By GPT-4, the model could tackle graduate-level problems on standardised tests. These advancements are marked by continuous improvement, with certain capabilities appearing abruptly at specific scales, known as 'emergent' capabilities.
The exact reasons why scaling confers these capabilities remain elusive. Theoretical explanations, such as increased capacity for feature representation enabling compositional reasoning or the existence of implicit curriculums within the data, only partially explain the phenomenon. The field of mechanistic interpretability, pursued by institutions like Anthropic and OpenAI, aims to uncover what computations are performed within these models. Researchers have identified distinct 'circuits' responsible for tasks like entity recognition and syntactic agreement, but a comprehensive understanding of how these components integrate to produce the model's behaviour is still incomplete.
What this means for what they are
Three insights help clarify the nature of these models. Firstly, they are not repositories of factual information. While they hold vast amounts of implicit knowledge within their parameters, their responses are generated on-the-fly, drawing from patterns rather than fixed tables of facts. This mechanism explains why they might confidently provide incorrect information; they are not retrieving facts but synthesising probable continuations from their trained data distribution.
Secondly, the simplification that these models merely complete sentences belies their complexity. While next-token prediction is their fundamental task, the sheer scale of these models has endowed them with intricate representations of meaning, logic, and even rudimentary planning abilities. Referring to them as simple autocompletes may capture their operational core but misses the substantive depth achieved at scale.
Thirdly, these models do not maintain persistent memories across sessions, except when explicitly designed to do so. Each interaction begins afresh, with the model's understanding limited to the current context window. The sense of continuity arises from the model's adeptness at maintaining thematic and referential consistency within a session. What a user perceives as memory is the model's capacity for contextually coherent generation, rather than a stored history of past interactions.
When interpreting claims about AI's capabilities, it is crucial to consider the underlying mechanics. A model's ability to solve complex problems does not guarantee competence in seemingly simpler tasks, like counting, because it lacks explicit symbolic reasoning. A model's false assertions are not lies; they result from probabilistic synthesis rather than deceptive intent. While these systems may appear to understand, their 'understanding' stems from pattern matching, not genuine comprehension. Nevertheless, the outputs they generate are undeniably practical, frequently impressive, and evolving rapidly.
In the broader discourse on AI, it is vital to separate the mechanisms from the myths. The underlying process is a loop of prediction and synthesis, guided by vast training data and formidable computational infrastructure. The real question is not what the models are doing but what we, as a society, choose to do with the capabilities they afford. The challenge lies not in the technicalities of their operation but in the ethical, social, and philosophical implications of their deployment.
References
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 30.
- Mikolov, T., et al. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv:1301.3781.
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 35.
- Olah, C., et al. (2022). A Mathematical Framework for Transformer Circuits. Anthropic.


